
Draw from .
Draw graphs of your own.
Data Pen is a prototype research tool for humanities data. Connecting linked data sources to filtering and graphing tools, Data Pen provides a framework for humanities researchers to access, explore, and manipulate multidimensional historical data.
Pull in data from established sources.
By connecting to authorities and archives like VIAF, the Library of Congress, Geonames, and Wikidata, Data Pen empowers researchers with the interconnected knowledge of the scholarly community and the larger linked data ecosystem.
Import data en masse from sources as a starting point, or use them as a reference to enrich datasets built one entity at a time. Either way, a node labelled “John Locke” can be identified as a person with already defined relationships to other people, places, and objects in the data set.
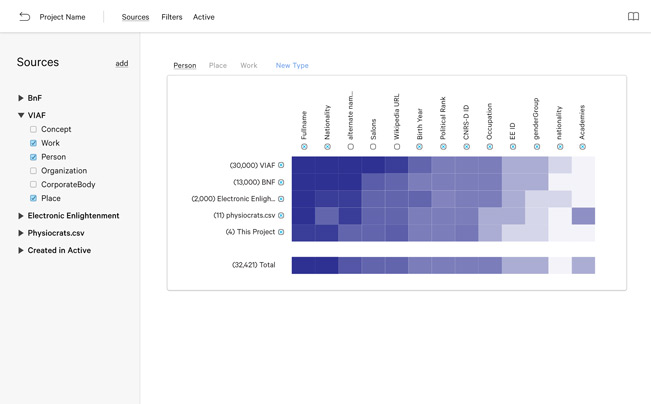
Filter and investigate your dataset.
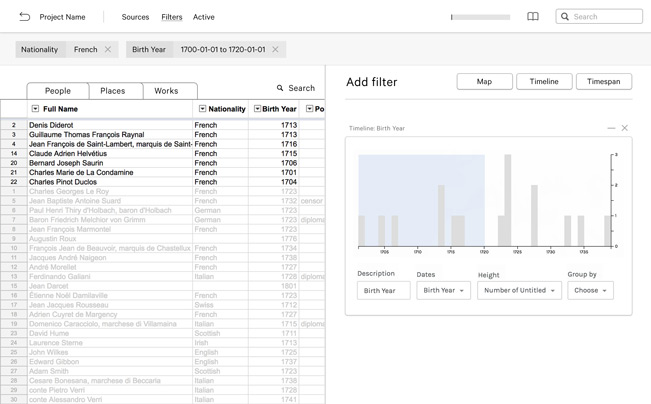
Having access to multiple archives’ worth of data means needing a way to navigate that data. Data Pen’s filtering tools provide a variety of ways to explore the rich web of linked data available to researchers, and to focus on what’s important.
Make your dataset more manageable with visual filters like timelines and facet filters, as well as tabular filtering tools. Use those same tools to investigate large and small datasets, in both tabular and visualised forms, to develop a contextual understanding of the data that’s available.
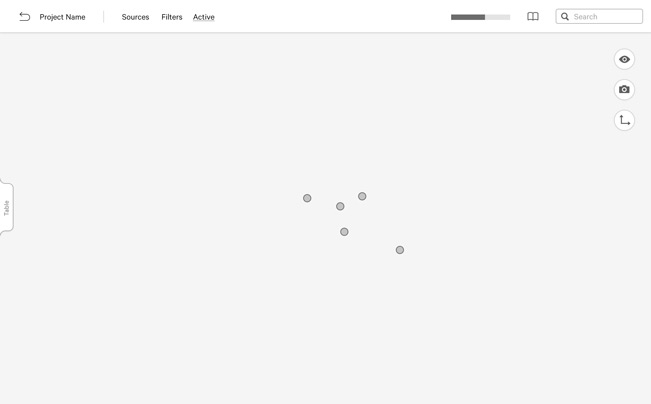
Draw with data.
Data Pen leverages linked data to aid researchers, not to replace them. Use the canvas as a blank slate to think visually, accompanied by a tabular view to keep the data close at hand. Add, remove, and edit nodes as your research shifts, and construct graphs that are meaningful to you.
Create, arrange, group, and annotate nodes by hand, or utilise the underlying data to help you. Select an entity on the canvas, and pull in any people or places associated with them. Save snapshots of your canvas to return to later, or to share with colleagues. Nothing moves unless you want it to.
Core team
Dan Edelstein Stanford University
Nicole Coleman Stanford University Libraries
Eetu Mäkelä University of Helsinki / Aalto University
Ethan Jewett Coredatra
Alex Sherman Center for Spatial and Textual Analysis
Tim Busuttil University of Technology, Sydney
Thomas Ricciardiello University of Technology, Sydney
Consultants and participants
Ruth Ahnert Queen Mary University of London
Sebastian Ahnert University of Cambridge
Arno Bosse Oxford University
Simon Burrows University of Western Sydney
Paolo Ciuccarelli Politecnico di Milano
Marten Düring University of Luxembourg
Paula Findlen Stanford University
Mauricio Giraldo New York Public Library
Jo Guldi Brown University
Howard Hotson Oxford University
Eero Hyvönen Aalto University
Matthew Jones Columbia
Christoph Kudella University College Cork
Miranda Lewis Oxford University
Matthew Lincoln Getty Research Institute
Jacqueline Lorber Kasunic University of Technology, Sydney
Sarah Ogilvie Stanford University
Iréne Passeron CNRS Paris
Miriam Posner UCLA
Rob Sanderson J. Paul Getty Trust
Philip Schreur Stanford University Libraries
Daniel Shore Georgetown University
Sarah Sussman Stanford University Libraries
Kate Sweetapple University of Technology, Sydney
Thomas Wallnig University of Vienna
Chris Warren Carnegie Mellon University
Scott Weingart Carnegie Mellon University
Caroline Winterer Stanford University
Funding and support
The Data Pen Project became real thanks to an ACLS Digital Extension grant.
We are also very fortunate for our affiliation with CESTA, the hub of all of our activities. The researchers and staff there are crucial to the success of the project. We also rely heavily on our partnership with the Stanford University Libraries for technical expertise and sharing ideas to create research tools that make the most of the digital library.
